无
”python 爬虫 安全 数据收集“ 的搜索结果
基于python的网络爬虫爬取天气数据及可视化分析 python程序设计报告 源代码+csv文件+设计报告 python期末简单大作业(自己写的,重复率低) 利用python爬取了网站上的城市天气,并用利用可视化展示,有参考文献有...
Python爬虫在数据收集、网络监测、自动化测试等领域有着广泛的应用。 Python爬虫的资源介绍可以从以下几个方面进行: 爬虫库:Python拥有丰富的爬虫库,如requests、BeautifulSoup、Scrapy等。这些库提供了各种...
前几天小伙伴在写报告时,和我讨论了一下爬取某生态网站的统计数据问题,我看了一下,这个网站是动态加载的,想了一想,很多数据网站的数据都是动态加载的,那么脆写一个案例吧,方便大家进行数据收集和整理。...

python爬虫基础
标签: 爬虫
人工收集数据(比如问卷调查) 在上面的来源中:人工的方式费时费力,免费的数据网站上的数据质量不佳,很多第三方的数据公司他们的数据来源往往也是爬虫获取的,所以获取数据最有效的途径就是通过爬虫爬取
爬虫(Web Crawler)是一种自动化程序,用于从互联网上收集信息。其主要功能是访问网页、提取数据并存储,以便后续分析或展示。爬虫通常由搜索引擎、数据挖掘工具、监测系统等应用于网络数据抓取的场景。 爬虫的...
爬虫(Web Crawler)是一种自动化程序,用于从互联网上收集信息。其主要功能是访问网页、提取数据并存储,以便后续分析或展示。爬虫通常由搜索引擎、数据挖掘工具、监测系统等应用于网络数据抓取的场景。 爬虫的...
python爬虫程序可用于收集数据。这也是最直接和最常用的方法。由于爬虫程序是一个程序,程序运行得非常快,不会因为重复的事情而感到疲倦,因此使用爬虫程序获取大量数据变得非常简单和快速。 由于99%以上的网站是...
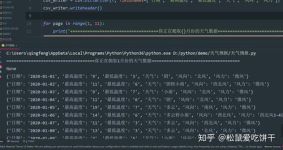

爬虫(Web Crawler)是一种自动化程序,用于从互联网上收集信息。其主要功能是访问网页、提取数据并存储,以便后续分析或展示。爬虫通常由搜索引擎、数据挖掘工具、监测系统等应用于网络数据抓取的场景。 爬虫的...
爬虫通常由搜索引擎、数据挖掘工具、监测系统等应用于网络数据抓取的场景。 爬虫的工作流程包括以下几个关键步骤: URL收集: 爬虫从一个或多个初始URL开始,递归或迭代地发现新的URL,构建一个URL队列。这些URL...
Python爬虫源码大放送:抓取数据,轻松搞定! 想轻松抓取网站数据,却苦于技术门槛太高?别担心,这些源码将助你轻松搞定数据抓取,让你成为网络世界的“数据侠盗”。 它们还具有超强的实用价值。无论你是想要分析...
毕业设计-基于python网络爬虫的二手房源数据采集及可视化分析设计与实现
爬虫(Web Crawler)是一种自动化程序,用于从互联网上收集信息。其主要功能是访问网页、提取数据并存储,以便后续分析或展示。爬虫通常由搜索引擎、数据挖掘工具、监测系统等应用于网络数据抓取的场景。 爬虫的...
爬虫(Web Crawler)是一种自动化程序,用于从互联网上收集信息。其主要功能是访问网页、提取数据并存储,以便后续分析或展示。爬虫通常由搜索引擎、数据挖掘工具、监测系统等应用于网络数据抓取的场景。 爬虫的...
Python爬虫源码大放送:抓取数据,轻松搞定! 想轻松抓取网站数据,却苦于技术门槛太高?别担心,这些源码将助你轻松搞定数据抓取,让你成为网络世界的“数据侠盗”。 它们还具有超强的实用价值。无论你是想要分析...

爬虫(Web Crawler)是一种自动化程序,用于从互联网上收集信息。其主要功能是访问网页、提取数据并存储,以便后续分析或展示。爬虫通常由搜索引擎、数据挖掘工具、监测系统等应用于网络数据抓取的场景。 爬虫的...

爬虫(Web Crawler)是一种自动化程序,用于从互联网上收集信息。其主要功能是访问网页、提取数据并存储,以便后续分析或展示。爬虫通常由搜索引擎、数据挖掘工具、监测系统等应用于网络数据抓取的场景。 爬虫的...
没错,使用Python网络爬虫,就可以从浩瀚的互联网中获取海量数据,它为人工智能扫除了大数据搜集的障碍。 本课程详细介绍了Python网络爬虫的知识,并通过详细的项目案例,让你快速成为网络爬虫高手。 3.Python数据...
Python爬虫是一种自动化程序,它可以模拟人类在互联网上的行为,从而自动收集互联网上的信息。因此,Python爬虫在各个领域都非常有用,比如信息抓取、数据分析、机器学习等等。 学会Python爬虫需要了解以下五个方面...
爬虫通常由搜索引擎、数据挖掘工具、监测系统等应用于网络数据抓取的场景。 爬虫的工作流程包括以下几个关键步骤: URL收集: 爬虫从一个或多个初始URL开始,递归或迭代地发现新的URL,构建一个URL队列。这些URL...
爬虫(Web Crawler)是一种自动化程序,用于从互联网上收集信息。其主要功能是访问网页、提取数据并存储,以便后续分析或展示。爬虫通常由搜索引擎、数据挖掘工具、监测系统等应用于网络数据抓取的场景。 爬虫的...
爬虫通常由搜索引擎、数据挖掘工具、监测系统等应用于网络数据抓取的场景。 爬虫的工作流程包括以下几个关键步骤: URL收集: 爬虫从一个或多个初始URL开始,递归或迭代地发现新的URL,构建一个URL队列。这些URL...
爬虫通常由搜索引擎、数据挖掘工具、监测系统等应用于网络数据抓取的场景。 爬虫的工作流程包括以下几个关键步骤: URL收集: 爬虫从一个或多个初始URL开始,递归或迭代地发现新的URL,构建一个URL队列。这些URL...
推荐文章
- c语言链表查找成绩不及格,【查找链表面试题】面试问题:C语言学生成绩… - 看准网...-程序员宅基地
- 计算机网络:20 网络应用需求_应用对网络需求-程序员宅基地
- BEVFusion论文解读-程序员宅基地
- multisim怎么设置晶体管rbe_山东大学 模电实验 实验一:单极放大器 - 图文 --程序员宅基地
- 华为OD机试真题-灰度图恢复-2023年OD统一考试(C卷)-程序员宅基地
- 【机器学习】(周志华--西瓜书) 真正例率(TPR)、假正例率(FPR)与查准率(P)、查全率(R)_真正例率和假正例率,查准率,查全率,概念,区别,联系-程序员宅基地
- Python Django 版本对应表以及Mysql对应版本_django版本和mysql对应关系-程序员宅基地
- Maven的pom.xml文件结构之基本配置packaging和多模块聚合结构_pom <packaging>-程序员宅基地
- Composer 原理(二) -- 小丑_composer repositories-程序员宅基地
- W5500+F4官网TCPClient代码出现IP读取有问题,乱码问题_w5500 ping 网络助手 乱码 send(sock_tcps,tcp_server_buff,-程序员宅基地